This post is for those who already understand the concept of stream processing and basic functionality of Kafka and Spark.And this post is also for people who are just dying to try Kafka and Spark right away. :)
Purpose
Setup a simple pipeline for stream processing in your local machine.
Integrate Spark consumer to the Kafka.
Implement a word frequency processing pipeline.
The versions of components in this post will be:
Kafka: 0.10.1.0 with scala 2.11
Spark streaming: 2.10
Spark streaming kafka: 2.10
Setup
Step 1 Install Kafka:
wget http://ftp.meisei-u.ac.jp/mirror/apache/dist/kafka/0.10.1.0/kafka_2.11-0.10.1.0.tgz
tar -xzf kafka_2.11-0.10.1.0.tgz
cd kafka_2.11-0.10.1.0
In this post I’m going to show how to import data into DynamoDB table.
Before we start, you show
Have a AWS account with access to the services we are gonna need.
Massive data that you badly want to import into a DynamoDB table.
Roughly, the steps to achieve our goal is preparing a file containing the data you want to insert into the table onto S3, and using Amazon Data Pipeline to import this S3 file to your DynamoDB Table.
Pretty simple and straight.
Step 1: Prepare the data.
Basically, your data is the content of items you want to insert into the table.
So, for each item you wanna insert you put one line in json style to a file like this:
But in general, this pattern has following features:
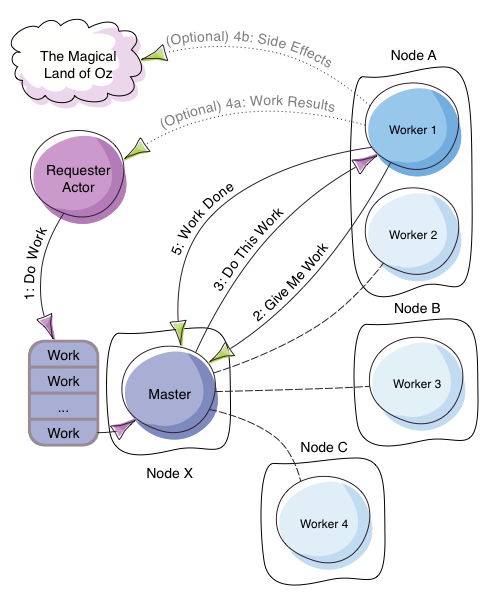
The system consists of one master and several workers.
The master receives tasks and send them to workers.
Workers work on and finish these tasks.
The master will track the status of worker**s, and only send task to *workers that is not currently working. (By doing so, we can achieve load balance.)
After worker finishes its task, it will send message back to the master, telling master that it is not working now.
To achieve our objectives, we are going to:
Make master into a container.
Make a group of workers into another container.
After we deploy above containers, we start another group of workers in another container. (To confirm the hot scale-out)
Implementation
As the features described above, writing master and worker is pretty straight forward. You can find detailed source code about this pattern at the bottom of that post.
Here is the system that I simplified:
TaskWorker
packageactorsimportactors.TaskMaster._importactors.TaskWorker.WorkFinishedimportakka.actor.{Actor,ActorLogging,ActorPath,ActorRef}objectTaskWorker{caseclassWorkFinished(isFinished:Boolean=true)}abstractclassTaskWorker(masterPath:ActorPath)extendsActorwithActorLogging{valmaster=context.actorSelection(masterPath)overridedefpreStart()=master!NewWorker(self)// TODO: add postRestart function for better robustness
defworking(task:Any,masterRef:ActorRef):Receive={caseWorkFinished(isFinished)=>log.debug("Worker finished task.")masterRef!TaskResponse(self,isFinished)context.become(idle)}defidle:Receive={caseTaskIncoming=>master!TaskRequest(self)caseTaskTicket(task,taskOwner)=>log.debug("Worker get task.")context.become(working(task,sender()))work(taskOwner,task)caseTaskConsumedOut=>log.debug("Worker did not get any task.")}defreceive=idledeffinish():Unit={self!WorkFinished(isFinished=true)}deffail():Unit={self!WorkFinished(isFinished=false)}defwork(taskOwner:Option[ActorRef],task:Any):Unit// define this method if you want to deal with the result of processing
// def submitWork(workResult: WorkerResult): Unit
}
TaskMaster
packageactorsimportactors.TaskMaster._importakka.actor.{Actor,ActorLogging,ActorRef}importscala.collection.mutable// companion object for protocol
objectTaskMaster{caseclassNewWorker(worker:ActorRef)caseclassTaskList(taskList:List[Any])caseclassTaskIncoming()caseclassTaskResponse(worker:ActorRef,isFinished:Boolean=true)caseclassTaskRequest(worker:ActorRef)caseclassTaskConsumedOut()// Add original sender of task, so that worker can know who send this.
// In that case, worker can directly send result of the task to the original sender
// Change the type of `task` to apply more specified task, or you can define you own task.
caseclassTaskTicket(task:Any,taskOwner:Option[ActorRef])}classTaskMasterextendsActorwithActorLogging{valtaskQueue=mutable.Queue.empty[Object]valworkers=mutable.Map.empty[ActorRef, Option[TaskTicket]]overridedefreceive:Receive={// when new worker spawns
caseNewWorker(worker)=>context.watch(worker)workers+=(worker->None)notifyFreeWorker()// when worker send task result back
caseTaskResponse(worker,isFinished)=>if(isFinished)log.debug(s"task is finished.")elselog.debug(s"task failed to finish.")workers+=(worker->None)self!TaskRequest(worker)// when worker want task
caseTaskRequest(worker)=>if(workers.contains(worker)){if(taskQueue.isEmpty)worker!TaskConsumedOut()else{if(workers(worker)==None){valtask=taskQueue.dequeue()assignTask(task,worker)}else{// this will never happen
log.error("Some worker is requiring task while processing the task.")}}}// when receive tasks
caseTaskList(taskList:List[Object])=>taskQueue.enqueue(taskList:_*)notifyFreeWorker()}defassignTask(task:Object,worker:ActorRef)={workers+=(worker->Some(TaskTicket(task,Some(self))))worker!TaskTicket(task,Some(self))}defnotifyFreeWorker()={if(taskQueue.nonEmpty)workers.foreach{case(worker,m)ifm.isEmpty=>worker!TaskIncoming()case_=>log.error("Something wired in the worker map!")}}}
Start the system
Our system should have two entries: one for starting the master, and the other is starting the worker to be connected to the master.
importjava.util.UUIDimportjava.util.concurrent.TimeUnitimportakka.actor.{ActorPath,ActorSystem,Props}importakka.routing.RoundRobinRouterimportcom.typesafe.config.ConfigFactoryimportactors._importscala.concurrent.duration.DurationobjectStartNode{valsystemName="load-balance"valsystemConfigKey="load-balance"valsystemNodeConfigKey="node"valmasterNodeConfigKey="master"valworkerNodeConfigKey="worker"valworkerNodePopulationConfigKey="population"valconfigHostKey="host"valconfigPortKey="port"valmasterActorName="master"// pattern used to get actor location
valmasterPathPattern=s"akka.tcp://$systemName@%s:%s/user/$masterActorName"defmain(args:Array[String]):Unit={if(args.length==1){args(0)match{case"worker"=>startAsWorkerGroup()case"master"=>startAsMaster()case_=>println(s"Can not parse start mode: ${args(0)}")}}else{println(s"Please choose start mode.")}}defstartAsWorkerGroup():Unit={println("Start actor system ...")valsystem=ActorSystem(systemName,ConfigFactory.load.getConfig(systemConfigKey))valworkerNodeConfig=ConfigFactory.load.getConfig(systemNodeConfigKey).getConfig(workerNodeConfigKey)valmasterNodeConfig=ConfigFactory.load.getConfig(systemNodeConfigKey).getConfig(masterNodeConfigKey)println("Parse worker config ...")// get worker config
valworkerCounter=workerNodeConfig.getInt(workerNodePopulationConfigKey)println("Connect to master ...")// connect to master
valmasterHost=masterNodeConfig.getString(configHostKey)valmasterPort=masterNodeConfig.getInt(configPortKey)valmasterLocation=masterPathPattern.format(masterHost,masterPort)println(s"to location $masterLocation")println("Connect to agent ...")valmasterOpt=try{Option(system.actorSelection(masterLocation))}catch{casex:Throwable=>Option.empty}if(masterOpt.isEmpty){println("Can not connect to master node!")}else{println("Worker Start!")valworkerGroup=system.actorOf(Props(newDemoWorker(ActorPath.fromString(masterLocation))).withRouter(RoundRobinRouter(workerCounter)))}}defstartAsMaster():Unit={println("Master Start!")println("Parse master config ...")println("Start actor system ...")valsystem=ActorSystem(systemName,ConfigFactory.load.getConfig(systemConfigKey))println("Spawn master ...")valmaster=system.actorOf(Props(newTaskMaster()),name=masterActorName)/* Test this system with a scheduled task sending tasks to master */valscheduler=system.schedulervaltask=newRunnable{defrun(){// create random task
valtask=s"Task:${UUID.randomUUID().toString}"master!List(task)}}implicitvalexecutor=system.dispatcherscheduler.schedule(initialDelay=Duration(2,TimeUnit.SECONDS),interval=Duration(1,TimeUnit.SECONDS),runnable=task)}}
Configuration
There are basically two kinds of things should be set in the config file.
The binding information of local actor system.
The remote actor system that is going to be connected.
Since the master can get worker’s location when worker send message to ask for connection,
we can only set the location information of master.
When above commands are executed, you will see the message indicating that workers has been connected to the master in the master’s log file.
And that is how the use docker and Akka to build a load balanced distributed system.
Please make sure your master and workers are in the same VPC network when deploy onto AWS’s EC2 servers.
Improvements
Currently, deployments need different config files, which is annoying. You can use --env-file and -e to forge a config file inside the container, so that role-based config is no longer needed. Only a config template will be needed.
It is ok that we add worker node to our master node on runtime. But when we try to disconnect worker node from master node, there will be something wrong. We can add a mechanism to detect dying worker and disconnect them.
You can find above source code at:
https://github.com/visualskyrim/scala-akka-loadbalance-pattern-with-docker
UPDATE 2016-02-03: Change of the opinion of deviding table into smaller ones.
BigQuery is a very powerful data analytics service.
A very heavy query on massive data may only take seconds in BigQuery.
Among all the interesting features of BigQuery, one thing you should most keep in mind,
is the way BigQuery charge your money.
How does BQ charge you
In general, it charges you for the size of the data you evaluate in your query.
The more data your query evaluate, the poorer BQ will get you.
One thing that will draw attention is what kind of operation will be considered as EVALUATE?
Basically, every column mentioned in your query will be considered as evaluated data.
Let’s see. For example, I have a table with around 1,000,000 rows’ data, which is around 500 MB in total.
First, let’s fetch all the data from the table:
SELECT*FROM[ds.fat_table]
Because this query directly fetches all the data from the table, the size of data will be charged is, without doubt, 500MB.
If we only fetch a part of the columns, the cost will dramatically fall.
SELECTcol1,col2FROM[ds.fat_table]
According to the actual total size of data of col1 and col2, BQ will just charges you the size of data you fetched.
If the data of col1 and col2 in this table is 150MB only, this query will charge you 150MB.
But the size of evaluated data is not only the size of fetched data.
Any column appears in WHERE, GROUP BY, ORDER BY, PARTITION BY or any other functions,
will be considered as “evaluated”.
The charged size of data is not just the total size of data in col1 and col2,
but the total size of col1, col2, col3, because col3 is in the WHERE clause.
If the data in col3 is 30MB, then the query will charge you 180MB in total.
Note all the data in col3 will be charged, not just the part that IS NOT NULL.
Actually, BigQuery did optimize the pricing for us.
If there is some columns is not necessary in the SELECT list of a sub-query,
BigQuery will not charge you for that.
As you can see, even if we selected all the columns in the table,
BQ will not charge all of them.
In this case, only the data of col1, col2, col3 will be charged.
Tips on optimizing charge
After knowing how BigQuery would charge us,
it will be clear on how to save our money.
Here is some tips I concluded from the experience of using BigQuery.
Tip 0: Make sure you need BigQuery
This is not actually a tip, but a very important point before you start to use BQ.
In general, BigQuery is designed to deal with massive data,
and of course designed to charge from processing the massive data.
If you don’t have the data that can’t be processed by your current tech,
you could just keep using MySQL, SPSS, R, or even Excel.
Because, well, they’re relatively cheap.
Tip 1: Do use wildcard function
This will be your very first step to save money on BigQuery.
Let’s say, we have a log_table to store all the access log lines on the server.
If I want to do some query on only one or two day’s log, for instance,
get the users who accessed to the server in certain days,
there is nothing I can do rather that:
This would cost you tons of coin if your website have, sadly, millions of users,
while you can actually achieve this free.
You can just:
Import newly created users of each day into different tables following wildcard pattern.
Call API to get the number of rows in each table, which is free.
There are many usecase just like this:
the sessions of each day, the transaction of each day, the activities of each day.
They are all free.
Tip 3: Separate tables carefully
Maybe after the first tip, you may think: “Yeah, query against the data that I only need as much as possible right? Let’s separate our table as tiny as possible lol.”
That’s a trap.
BigQuery does charge of the size of data we use in the query, BUT, in the unit of 10MB.
Meaning, even if I have query query that only uses 1kb of data, this query will be charged 10MB.
For example, if you are running a B2B service which consists hundreds of shops in your system.
So, you don’t just separate your table by date, you also separate the table by shop with shop_id.
But in each table you only have less than 1MB data.
If you have to use this access_log table to generate another kind of tables separated by shop,
you will be charged by 10MB * <num-of-shops> * <number-of-days>,
while if you don’t separate access_log table by shop you will be charged 1MB * <num-of-shops> * <number-of-days> in the worst case.
So, is it bad idea to separate tables other than dates?
NO, it depends.
As you can see, if the size of access_log for each shop on each day is around 10MB or even bigger,
this design is actually perfect.
So, whether separate further depends on the size of your data.
The point is to know the granularities of your data before you make the decision.
Update 2016-02-03:
Actually, dividing table by not only date but also some other id will make BigQuery not functioning well.
According to my own experience, I have 20000+ tables in one dataset separated by both dates and a id.
The tables look like [table_name]_[extra_id]_[date_YYmmdd].
And following issues will truly happen:
BigQuery’s API call will fail with InternalException occasionally. This will happen to the API call used to create empty table with given schema.
There are following three kinds of time record in each query you have fired. Usually the interval between first one and second one is less than 1 second. When you have a lot of tables like my case, the gap between creationTime and startTime could last 20 seconds.
creationTime: The time when your request arrives the BQ server.
startTime: The time BQ server to start execute the Query.
endTime: The time that BQ server finishes you query or finds it invalid.
BigQuery start to be not able to find your table. There will be query failing because of errors like FROM clause with table wildcards matches no table or **Not found: Table **, while you know exactly the tables do exist. And when you run the failed query again without fixing anything, the query will dramatically succeed.
So, I STRONGLY recommend not to use too many tables in the same dataset.
Tip 4: Think, before use mid-table
The mid-table is the table you use to store the temporary result.
Do use it when:
There will be more than one queries going to use this mid-table.
Let’s say, by doing query A, you get the result you want.
But there is another query B using the sub-query C within query A.
If don’t use mid-table, you will be charged by:
sub-query C
remaining query in A after sub-query C
sub-query C
remaining query in B after sub-query C
But if you use mid-table to store the result of sub-query C,
you will be charged by:
sub-query C
remaining query in A after sub-query C
remaining query in B after sub-query C
By doing this, you can save at least the money cost by the data of the size of the mid-table.
Do NOT use it when:
If you only fear your query is too long, while there is no other query using the mid-table you generate.
Not all people will agree on this.
Some people may start to say “This is too nasty”, “God, this query is too fat.” or even “WTF is this?”.
Well, generate mid-table in this situation surely charging you more.
I will just choose save more of my money.
And if you format your query well, no matter how long your query grows,
it will still looks nice.
_
So, these tips are some thing I concluded these days, hope they help you,
and save your money.
Currently I was working on analytics with BigQuery.
It was quite a experience that you could accomplish any process on mass data
without considering any subtle performance issue.
The greatness and the thinking of the internal implementation of BigQuery is not going
to be discussed here.
Here I’m going to show how to use BigQuery to Calculate users’ access session from
your access log with one query.
First, let’s define the session.
A session is a sequence of a user’s access. Each access in the sequence is no more
than a specific period of time before the next access.
The length of a session is the period of time after the first access in this session and
the last access in this session.
Then, we need to describe the table which stores the data from the access log.
At least we should have following two column in this table:
access_time: a timestamp that represents the time when access happen. In our case, let’s say 30 minute.
user_id.
And now we could start to make the query step by step:
Step 1: preprocess the log table:
In this step, we do some type converting to make the calculation in the following
steps easier:
SELECTuser_id,TIMESTAMP_TO_SEC(access_time)ASaccess_time_sec,-- Convert timestamp to secondsFROMds.access_log_table-- This is the table where you put your log data into
Step 2: find the last access to the current access
After last step, we now have every access for each row.
In this step, we are going to add a column to represent last access to the access in each row.
SELECTuser_id,access_time_sec,-- The lag + partition + order combination is to get the previous access to the current access in the rowLAG(access_time_sec,1)OVER(PARTITIONBYuser_idORDERBYaccess_time_sec)ASprev_access_time_secFROM(-- previous query-- SELECT-- user_id,-- TIMESTAMP_TO_SEC(access_time) AS access_time_sec, -- Convert timestamp to seconds-- FROM-- ds.access_log_table -- This is the table where you put your log data into-- previous query end)
The LAG function is used with PARTITION BY, which is used to get the specific column of the previous row
in the same partition.
The partition is separated by PARTITION BY function, while the order within the partition is specified
by ORDER BY inside the OVER statement.
In this case, we separate all the accesses in the partitions for each user by
PARTITIONBYuser_id
Then, to make sure the order of time in each partition, we order each partition with:
PARTITIONBYuser_idORDERBYaccess_time_sec
To get the access_time_sec of previous row, we do:
More details about function LAG, you can refer to the Doc.
Of course, like what you might be thinking of right now, for each partition,
the first row in each partition doesn’t have the prev_access_time_sec`.
In the result, it will be **null at this point.
Leave it like that, and we will deal with it later.
Step 3: Decide whether an access is the beginning of a session
In this step, we are gonna tag each access whether it is the beginning of sessions.
And as we said already, a session will break if the next session is 30 minute after current session.
To achieve that, we do:
SELECTuser_id,access_time_sec,prev_access_time_sec,IFNULL-- The first access of each partition is the beginning of session by default.(access_time_sec-prev_access_time_sec>=30*60,TRUE)ASstart_of_sessionFROM(-- previous query-- SELECT-- user_id,-- access_time_sec,-- -- The lag + partition + order combination is to get the previous access to the current access in the row-- LAG(access_time_sec, 1) OVER (PARTITION BY user_id ORDER BY access_time_sec) AS prev_access_time_sec-- FROM-- (-- SELECT-- user_id,-- TIMESTAMP_TO_SEC(access_time) AS access_time_sec, -- Convert timestamp to seconds-- FROM-- ds.access_log_table -- This is the table where you put your log data into-- previous query end-- ))
As we just said, the first access in each partition can only have prev_access_time_sec as null.
So they’re considered as the beginning of session by default.
Step 4: Decide whether the access is the end of session
Things become complex from here.
To achieve the goal of this step, we take two select s.
First we tag each row(access) with whether the next access is the beginning of the session in the partition with the same user_id:
SELECTuser_id,access_time_sec,prev_access_time_sec,LEAD(start_of_session,1)OVER(PARTITIONBYuser_idORDERBYaccess_time_sec,prev_access_time_sec)is_next_access_sosFROM(-- previous query-- SELECT-- user_id,-- access_time_sec,-- prev_access_time_sec,-- IFNULL -- The first access of each partition is the beginning of session by default.-- (-- access_time_sec - prev_access_time_sec >= 30 * 60,-- TRUE-- ) AS start_of_session-- FROM-- (-- SELECT-- user_id,-- access_time_sec,-- -- The lag + partition + order combination is to get the previous access to the current access in the row-- LAG(access_time_sec, 1) OVER (PARTITION BY user_id ORDER BY access_time_sec) AS prev_access_time_sec-- FROM-- (-- SELECT-- user_id,-- TIMESTAMP_TO_SEC(access_time) AS access_time_sec, -- Convert timestamp to seconds-- FROM-- ds.access_log_table -- This is the table where you put your log data into-- previous query end-- )-- ))
Now we know for each access of each user, whether the next access is the beginning of the next session.
The reason why we need to know this, is, let’s consider this:
Let’s say there is one partition, which is already ordered by access_time, for a user like this following
The combination of start_of_session and is_next_access_sos and the meaning behind at this point must by one of the following:
| start_of_session | is_next_access_sos | this_access_must_be |
|------------------|--------------------|------------------------------------------------------------------------------------------------------------|
| true | false | the first access in the session with number of access >= 2 |
| true | true | the only access in the session |
| true | null | the only access in the session, and the last access in the partition |
| false | true | the last access in the session with number of access >= 2 |
| false | false | this access is not the first access nor the last in the session with number of access >= 3 |
| false | null | the last access in the session with number of access >=2, and this access is the last one in the partition |
Knowing this, we can easily get whether an access is the last access in the partition.
SELECTuser_id,access_time_sec,prev_access_time_sec,start_of_session,ISNULL(is_next_access_sos,TRUE)ASend_of_session-- if an access is the end of the partition, it must be the end of the sessionFROM(SELECTuser_id,access_time_sec,prev_access_time_sec,start_of_session,LEAD(start_of_session,1)OVER(PARTITIONBYuser_idORDERBYaccess_time_sec,prev_access_time_sec)is_next_access_sosFROM(-- previous query-- SELECT-- user_id,-- access_time_sec,-- prev_access_time_sec,-- IFNULL -- The first access of each partition is the beginning of session by default.-- (-- access_time_sec - prev_access_time_sec >= 30 * 60,-- TRUE-- ) AS start_of_session-- FROM-- (-- SELECT-- user_id,-- access_time_sec,-- -- The lag + partition + order combination is to get the previous access to the current access in the row-- LAG(access_time_sec, 1) OVER (PARTITION BY user_id ORDER BY access_time_sec) AS prev_access_time_sec-- FROM-- (-- SELECT-- user_id,-- TIMESTAMP_TO_SEC(access_time) AS access_time_sec, -- Convert timestamp to seconds-- FROM-- ds.access_log_table -- This is the table where you put your log data into-- previous query end-- )-- )))WHEREstart_of_sessionORis_next_access_sosISNULLORis_next_access_sos-- only get the start or the end of session in the result
After this step, we get all the accesses that are either the start or the end of a session in the result.
We have all the start and end access of sessions in our result set (some of them are both start and end).
It’s already very clear about how to get all the sessions now:
A session must have a start access
Then we rule out accesses that are not start access
We get all the sessions
But that’s not enough, nor fun.
Now let’s say we also need to know the duration of sessions. That sounds fun enough.
Let’s do the same trick again.
Remember, now we only have start and end access in the result of previous query.
So let’s get the access time of previous access for each access in each partition with same user_id:
SELECTuser_id,access_time_sec,LAG(access_time_sec,1)OVER(PARTITIONBYuser_idORDERBYaccess_time_sec,prev_access_time_sec)ASprev_access_time_sec_2start_of_session,end_of_sessionFROM(-- previous query-- SELECT-- user_id,-- access_time_sec,-- prev_access_time_sec,-- start_of_session,-- ISNULL(is_next_access_sos, TRUE) AS end_of_session -- if an access is the end of the partition, it must be the end of the session-- FROM-- (-- SELECT-- user_id,-- access_time_sec,-- prev_access_time_sec,-- start_of_session,-- LEAD(start_of_session, 1) OVER (PARTITION BY user_id ORDER BY access_time_sec, prev_access_time_sec) is_next_access_sos-- FROM-- (-- SELECT-- user_id,-- access_time_sec,-- prev_access_time_sec,-- IFNULL -- The first access of each partition is the beginning of session by default.-- (-- access_time_sec - prev_access_time_sec >= 30 * 60,-- TRUE-- ) AS start_of_session-- FROM-- (-- SELECT-- user_id,-- access_time_sec,-- -- The lag + partition + order combination is to get the previous access to the current access in the row-- LAG(access_time_sec, 1) OVER (PARTITION BY user_id ORDER BY access_time_sec) AS prev_access_time_sec-- FROM-- (-- SELECT-- user_id,-- TIMESTAMP_TO_SEC(access_time) AS access_time_sec, -- Convert timestamp to seconds-- FROM-- ds.access_log_table -- This is the table where you put your log data into-- previous query end-- )-- )-- )-- )-- WHERE-- start_of_session OR is_next_access_sos IS NULL OR is_next_access_sos -- only get the start or the end of session in the result)
Because of we only have start and end access in the result of previous query, the previous access time of each access must be either of following:
If the access is the start of session: this previous access time must be the end time of the previous session
If the access is not the start of session: this previous access time must be the the start time of the current session <– this is what we need
Be careful when think this through, there might be access that is both the start and the end of the session.
When we are clear with this, we can get all the sessions with duration:
SELECTuser_id,CASEWHENNOTstart_of_sessionANDend_of_sessionTHENaccess_time_sec-session_start_secWHENstart_of_sessionANDend_of_sessionTHEN0-- for sessions that only have one accessENDASduration,CASEWHENNOTstart_of_sessionANDend_of_sessionTHENSEC_TO_TIMESTAMP(session_start_sec)WHENstart_of_sessionANDend_of_sessionTHENSEC_TO_TIMESTAMP(access_time_sec)-- for sessions that only have one accessENDASsession_start_timeFROM(previousquerySELECTuser_id,access_time_sec,LAG(access_time_sec,1)OVER(PARTITIONBYuser_idORDERBYaccess_time_sec,prev_access_time_sec)ASsession_start_secstart_of_session,end_of_sessionFROM(SELECTuser_id,access_time_sec,prev_access_time_sec,start_of_session,ISNULL(is_next_access_sos,TRUE)ASend_of_session-- if an access is the end of the partition, it must be the end of the sessionFROM(SELECTuser_id,access_time_sec,prev_access_time_sec,start_of_session,LEAD(start_of_session,1)OVER(PARTITIONBYuser_idORDERBYaccess_time_sec,prev_access_time_sec)is_next_access_sosFROM(SELECTuser_id,access_time_sec,prev_access_time_sec,IFNULL-- The first access of each partition is the beginning of session by default.(access_time_sec-prev_access_time_sec>=30*60,TRUE)ASstart_of_sessionFROM(SELECTuser_id,access_time_sec,-- The lag + partition + order combination is to get the previous access to the current access in the rowLAG(access_time_sec,1)OVER(PARTITIONBYuser_idORDERBYaccess_time_sec)ASprev_access_time_secFROM(SELECTuser_id,TIMESTAMP_TO_SEC(access_time)ASaccess_time_sec,-- Convert timestamp to secondsFROMds.access_log_table-- This is the table where you put your log data intopreviousqueryend))))WHEREstart_of_sessionORis_next_access_sosISNULLORis_next_access_sos-- only get the start or the end of session in the result))WHERENOT(start_of_sessionANDNOTend_of_session)-- rule out the accesses that are only start of the sessions
Now we have all the sessions with user_id, duration and session_start_time.
The main points in constructing this query are:
use partition function to folder the table.
rule out the intervals between start and end of the session.
use partition function again to calculate the duration.

{kind=link}